目录
在读了南大jyy这篇system领域的顶会论文 The Hitchhiker's Guide to Operating Systems 后
再加上最近一直有在进行有关StateMachine(SM,状态机)的实践,有了一些心得,故在此总结记录一下。
文本会给出一些实践代码,其中包含了一些论文中所提到的模型(以现代C++复现),也有一些在我自己好奇心的驱逐下诞生的想法,又或者是一些生产中的最佳实践。
状态机作为第一公民
就像是函数在函数式编程当中作为第一公民一般,在论文当中,也将状态机作为了第一公民进行讲述。
Everything is a state machine.
论文的核心主题是用状态机来研究操作系统,无论是操作系统本身,还是在操作系统之上,或之下,都可以看作是状态机,这也是Everything的含义。
操作系统之上
操作系统之上就是用户程序。
我们从程序的构成来进行分析。
程序 = 算法 + 数据结构
这是一个较为熟知的观念。
可以这样去理解,数据结构用于存放程序运行时的状态,而算法给出了程序在各种状态之间进行转移的具体方法。
状态机 = 状态 + 转移条件
从这个角度来看,程序就是状态机。
关于将程序看作是状态机这点,论文中有较为详细的说明,我在这里就不做重复了。
下文对论文原文的翻译由DeepSeek给出,对于稍微有些不通顺或不恰当的地方,我做了一些小的修改,不过还是请以原文为准。
Every program run essentially boils down to the execution of binary instructions, whose behavior is rigorously defined by a state machine in which states are register/memory values and transitions are the execution of one instruction at the program counter
每个程序的运行本质上都可以归结为二进制指令的执行,其行为由状态机严格定义,其中状态是寄存器/内存中存放的值,状态转移就是执行程序计数器中的一条指令。
register/memory 是存放状态的关键,而状态转移就是取指执行。
操作系统本身
操作系统本身也是一个程序,只不过它是运行在裸机上的程序。
既然它是一个程序,那么它就是一个状态机。
操作系统的指责之一,是管理众多程序的运行。
在这方面,操作系统也是状态机的管理者。
各个程序的推进需要操作系统进行辅助,辅助手段就是系统调用。
例如,程序想要读取文件中的内容,它必须依靠read系统调用(在Linux中),这就是一个典型的状态转移,从对文件内容一无所知的状态,转移到了知悉文件内容的状态。
身为状态机的管理者,操作系统有了令人着迷的特权,它可以跟踪程序的运行。
程序的运行实际上就是一个状态转移到下一个状态,再转移到下下一个状态,以此类推。
那么便构成了一个状态转移的路径,操作系统拥有观测这条路经的权限和能力。
这条路经对于我们程序的调试来说,是大有好处的,这也是令我们着迷的核心原因之一。
操作系统之下
操作系统之下,就是各种各样的硬件。
操作系统不仅仅是程序的管理者,也是硬件资源的管理者。
自底向上,操作系统为程序抽象了硬件,使得硬件的使用更加便捷。
硬件本质上来说,就是一系列物理元器件以及其控制电路构成。
操作系统本身是一个软件,它所能交流的对象只能是控制电路。
将重点放在控制电路上,控制电路本身也是状态机。
如果你写过Verilog,应该接触过所谓的三段式状态机。
Verilog是一种对电路的描述语言,了解到这,应该对这个观点就不会有什么疑问了。
更原始的观点
我们尝试从更原始的角度考虑,图灵机,现代计算机的设计和编程语言的理论基础都可以追溯到图灵机。
图灵机(Turing Machine)是英国数学家阿兰·图灵(Alan Turing)于1936年提出的一种抽象计算模型,用于研究计算问题的可计算性。
计算机当然就是用来处理计算的机器,其构建的原理就是图灵机。
图灵机的工作过程可以描述为以下步骤(由DeepSeek给出):
- 初始化:纸带上包含输入符号串(其余部分为空白符号),读写头指向纸带的起始位置,状态寄存器设置为起始状态。
- 读取符号:读写头读取当前单元格的符号。
- 执行操作:根据当前状态和读取的符号,查找控制规则,决定下一步的操作(写入符号、移动读写头、改变状态)。
- 重复步骤2-3:直到图灵机进入终止状态(接受或拒绝状态),计算结束。
这么一看,图灵机不也是一种状态机吗?
从操作系统入手状态机
先想想,成为操作系统是一种什么样的体验?
好吧,其实人类并没有成为机器的可能(这是一个碳基生物向硅基生物转变的研究 笑
但我曾经在知乎上刷到过一个问题,“获取身体的root权限后是一种什么体验”
如果想知道成为操作系统是一种什么体验,不妨从这个问题下边的回答中先感受一番。
言归正传,这一节我们考虑使用现代C++,在用户态实现一个超级简陋的操作系统,它支持调度和运行状态获取,它的运行背景是一个单核的CPU,从模拟实现的角度来说,这个程序只有一个主线程。
别忘了,操作系统本身是一个状态机,同时也是状态机的管理者,我们以此来初步感受一下状态机,也感受一下协程和操作系统。
C++版本选取的是-std=c++23,因为核心需要采用C++ Coroutine来实现。
(值得注意的是,在论文当中,是使用Python进行实现的,提供的系统调用也更全面一些)
理解下面的实现,需要知悉C++ Coroutine运作的相关原理和细节,如果你没有这方面的基础,可以看看 这几篇文章,尤其是最早的三篇。
这个超级简陋的操作系统的完整代码你可以在这里查看。
骨架搭建
我的编译环境是gcc version 13.2.0 Ubuntu x86_64,编译指令如下:
shellg++ main.cxx -std=c++23 -o main
没错,因为足够简陋,一个源文件main.cxx就可以搞定了,也不需要其他依赖,标准C++足矣,运行一下看看。
shell% ./main user1 user2 user3
OS start...
user1 Hello
user2 Hello
user1 Hello
user1 Hello
user3 Hello
user3 Hello
user2 Hello
user2 Hello
user3 Hello
OS done...
因为调度是随机的,输出应该不会是一模一样的;从输出不难猜测它的骨架,代码如下所示:
cpp#include <random>
#include <string>
#include <vector>
#include <iostream>
#include <coroutine>
#include <functional>
#include <string_view>
class OS;
class process;
process init();
process user_main();
struct syscall_write;
struct syscall_spawn;
struct syscall_getname;
std::vector<std::string_view> names {};
process init() {
for (size_t i = 1; i < names.size(); i++) {
co_await syscall_spawn(user_main, names[i]);
}
}
process user_main() {
std::string name = co_await syscall_getname();
std::string out = name + " Hello";
for (int i = 0; i < 3; i++) {
co_await syscall_write(out);
}
}
int main(int argv, char** argc) {
for (int i = 0; i < argv; i++) {
names.emplace_back(argc[i]);
}
OS::getInstance()->run();
}
在这个简陋的例子中,进程定义为class process,操作系统定义为class OS,是一个单例类。
首先,操作系统启动后,会先创建一个init进程,它负责创建三个用户进程,用户进程会获取它自己的名称,并输出三次,这个名称是由命令行参数指定的。
这里所提到的init进程,是操作系统运行后启动的第一个进程,在Linux上对应为PID是1的进程。
系统调用介绍
系统调用是用户程序和操作系统交互的手段,没有了系统调用,用户程序可以说只能自嗨了。
Without system calls, the program (state machine) is a “closed world” that can only perform arithmetic and logical operations over memory and register values.
若无系统调用,程序(状态机)便是一个“封闭的世界”,仅能使用内存与寄存器,执行算术和逻辑操作。
我们提供了三个系统调用:
syscall_spawn创建新的进程syscall_getname获取进程的名称syscall_write输出一个字符串
系统调用需要配合关键字co_await来使用。
OS的实现
首先,操作系统会不断的推进某个进程,这个推进过程就是run函数。
其次,决定推进哪个进程,就是所谓的调度,由schedule函数负责,其本质是随机选取。
最后,我们要实现上述提到的三个系统调用。
cppclass OS {
public:
static OS* getInstance() {
static OS os;
return &os;
}
~OS() = default;
using UserProcessFunType = std::function<process(void)>;
void run() {
std::cout << "OS start...\n";
do_spawn(init, "init");
do {
auto process_it = schedule();
if (process_it == processes.end()) continue;
if (process_it->hasNext()) {
process_it->next();
} else {
processes.erase(process_it);
}
} while (!processes.empty());
std::cout << "OS done...\n";
}
void do_write(std::string_view str) {
std::cout << str << "\n";
}
void do_spawn(UserProcessFunType f, std::string_view name) {
auto p = f();
p.setName(name);
processes.emplace_back(p);
}
std::string_view do_getname(const std::coroutine_handle<process::promise_type>& handle) {
auto it = std::find_if(processes.begin(), processes.end(), [&](auto&& p) {
return p.handle == handle;
});
if (it == processes.end()) return "";
else return it->getName();
}
private:
OS() = default;
OS(const OS&) = default;
std::vector<process>::iterator schedule() {
std::uniform_int_distribution<> dis(0, processes.size());
return processes.begin() + dis(gen);
}
std::vector<process> processes {};
std::random_device rd {};
std::mt19937 gen { rd() };
};
我们需要关注的是run当中的do-while循环。
cppdo {
auto process_it = schedule();
if (process_it == processes.end()) continue;
if (process_it->hasNext()) {
process_it->next();
} else {
processes.erase(process_it);
}
} while (!processes.empty());
它从进程队列中,通过schedule随机选取了一个,随后通过hasNext判断是否满足推进条件,满足即可通过next推进运行,否则将它移出进程队列。
这里提到的推进条件,指的是其是否完成了运行,若是已经完成运行的进程,不应当再继续调度运行,并且应该移出进程队列。
再注意到do_getname的实现,它接受一个协程句柄handle,这个协程句柄和每个进程是一一对应的,这样操作系统就知道需要查找并返回哪个进程名称了。
至此,我们有了一个整体视图,进程是一个协程,而操作系统是协程的管理者。
每执行一次循环体,就是进程每一步的推进,也意味着一次状态的转移,所以对于推进这个动作,我命名为next,就是下一步/下一状态的含义。
进程的实现
进程本身是一个协程,而C++标准要求,成为一个协程需要提供一些固有的框架代码。
再就是,其需要满足操作系统所需,要实现next和hasNext等接口,用于推进状态和信息管理。
cppclass process {
public:
friend class OS;
struct promise_type {
// 开始执行时挂起
std::suspend_always initial_suspend() {
return {};
}
// 执行结束后挂起
std::suspend_always final_suspend() noexcept {
return {};
}
auto unhandled_exception() {}
process get_return_object() {
return { std::coroutine_handle<promise_type>::from_promise(*this) };
}
void return_void() {}
};
process() = default;
process(const std::coroutine_handle<promise_type>& handle_in) : handle { handle_in } {}
~process() = default;
bool hasNext() {
return !handle.done();
}
auto next() {
handle.resume();
}
void setName(std::string_view name_in) {
name = name_in;
}
std::string_view getName() {
return { name };
}
private:
std::coroutine_handle<promise_type> handle;
std::string name {};
};
struct promise_type的相关实现就是C++协程所需要的固有框架代码,本文的重点并不是实现协程的具体细节,在此就不多分析了。
开始执行时就挂起协程,是因为我们在进程创建之后,不应该马上就开始运行它,因为操作系统对进程的一些初始化工作还没有完成,并且应该由操作系统的调度来决定,应该什么时候开始运行。
一开始就挂起的协程,会在OS的do_spawn的f()处返回,继续完成do_spawn剩余的进程初始化逻辑。
我们注意到next函数的实现,它通过协程的句柄来恢复协程的执行。
在这里说明一下整体运行流程,每当协程挂起后,会从handle.resume返回,紧跟着就是next返回,运行权就返回到了OS的do-while当中,等待下次循环调用对应进程的next,就会进而调用handle.resume,然后恢复该进程所对应的,之前挂起的协程,这样运行权又回到了进程手中。
从这可以体现出的是,操作系统对进程的切换,但是上下文的保存和恢复是隐藏在协程背后的实现细节当中的,并不由我们直接管理。
每一次协程的挂起和恢复,都是运行权的交替,是从进程递交给操作系统,亦是从操作系统递交给进程。
我们通过对handle.resume进行了一个简单的包装,实现了推进的概念,也就是状态转移。
系统调用的实现
事实上,系统调用的核心逻辑已经在OS当中实现。
但是由于co_await关键字本身的需求,我们需要实现一系列struct syscall_xxx。
但是这都仅仅只是一层简单的包装,它们最终会通过await_suspend,调用OS当中对应的do_xxx函数。
在await_suspend结束后,运行权就递交到操作系统了。
syscall_write
cppstruct syscall_write {
syscall_write() = default;
syscall_write(std::string_view str_in) : str { str_in } {}
~syscall_write() = default;
std::string_view str {};
bool await_ready() { return false; }
void await_suspend(std::coroutine_handle<>) {
OS::getInstance()->do_write(str);
}
void await_resume() {}
};
syscall_spawn
cppstruct syscall_spawn {
syscall_spawn() = default;
syscall_spawn(OS::UserProcessFunType f_in, std::string_view name_in)
: f { f_in }, name { name_in } {}
~syscall_spawn() = default;
OS::UserProcessFunType f;
std::string_view name;
bool await_ready() { return false; }
void await_suspend(std::coroutine_handle<>) {
OS::getInstance()->do_spawn(f, name);
}
void await_resume() {}
};
syscall_getname
cppstruct syscall_getname {
syscall_getname() = default;
~syscall_getname() = default;
bool await_ready() { return false; }
void await_suspend(std::coroutine_handle<process::promise_type> handle) {
name = OS::getInstance()->do_getname(handle);
}
std::string await_resume() { return name; }
std::string name;
};
协程调度框架
我们实现的这个简陋版用户态操作系统,实际上就是一个协程调度框架。
只不过我们并没有引进异步多线程,这并不高效,但是就展示“状态转移”而言,已经足够。
现在我们应该有一个认知,把操作系统那一套对进程/线程的管理代码,从内核态搬到用户态,也是同样适用的。
所以会有协程就是用户态线程的说法。
但我们可以发现,协程需要通过co_await来主动放弃运行权,这样才有可能让操作系统运行。
而在真正的操作系统当中,显然不可能依靠进程主动放弃CPU,所以这也是需要时钟中断的原因之一。
C++ Coroutine由于出现时间比较晚,现在并不完善,只是提供了最基本的支持,后面还有很长的路要走。
目前Github上也出现了一些开源的协程基础设施,我接触的有两款,感兴趣的可以看看:
状态机带来的好处
我们已经初步感受了状态机理论,但是理论应该指导实践,接下来看看状态机会给我们带来一些什么好处。
梳理整体思路
我先给出这个想法的核心公式
状态机 = 状态转换图 => 流程图
状态机本身是一个抽象的模型,实际使用时我们需要画出状态转换图,可以说状态转换图就是状态机的具现。
状态图主要有两方面构成,一方面是所涉及的所有状态,另一方面是各个状态转移的条件。
从这个视角去讨论,我们很容易发现,在把状态转换图画出来之后,很容易将其迁移到流程图上。
或者说,可以在状态转换图的基础上,补充一些细节,就可以得到系统的流程图了。
状态转换图一般是在宏观上描述这个系统,通常情况下,每个状态都包装了很多细节在其中,因此每个状态本身也是一个状态机,只要你打算将某个状态当中的细节进一步展开。
画状态转换图本质上是在进行一种设计,也就是在宏观的角度上设计系统,想清楚什么时候干什么事。
宏观的视角为我们带来了一些好处,例如有助于全面理解系统各个模块,也就是拥有一个全局的视角,不再局限于某个具体模块当中的一些具体细节。
同时我们并没有失去深究细节的能力,就如上提到的,你随时可以根据需要,将某一个状态展开,进一步的研究其中包装的各种细节。
这里的重点是,我们可以根据需要,随时伸缩,既可以选择宏观,也可以选择微观,状态机为我们提供了这样的便利。
另外,这本质上也是一种设计意图先行的方案,在大多时候,我们都是一边写代码一边思考设计,这两种方法是有根本区别的。
在给出状态转换图后,相当于大体框架设计已经敲定,剩下的就是使用编程语言将其翻译实现,是一种“把事情想清楚,再动手”的理念。
对于架构/框架类的设计,显然是想清楚再动手会优于一边动手一边思考,后者使设计变得不稳定,随时可能发生变化,就好比建房子会先把地基打好,在这之上的设计可能会发生一些变化,但是打好的地基就不会再改变了。
总的来说,状态机为我们带来的一个好处就是,将事情整体上想明白,在需要时又可以深入细节。
跟踪状态转换
一个状态机当中包含了各种各样的状态,每个状态的细节不能一概而论。
但是状态的转换在抽象层面是统一的,用一句话概括就是,条件满足时从一个状态抵达下一个状态。
一个状态机的运行,就是状态的不断的转换,由此形成一条状态转换路径。
在这个转换的过程中,是可以被我们介入的,以此我们可以跟踪这条路经,为debug提供有力支持。
以我们上面所实现的简陋操作系统具体说明一下,我们关注do-while。
cppdo {
auto process_it = schedule();
if (process_it == processes.end()) continue;
if (process_it->hasNext()) {
// <--- 在此处介入,记录每个process_it
process_it->next();
} else {
processes.erase(process_it);
}
} while (!processes.empty());
我们介入状态转换的过程,可以记录下每个状态转换发生的时间,源状态,目的状态等信息。
只要你想,完全可以记录更加丰富的状态转换信息,当系统发生故障时,可以有效辅助debug。
例如,我们给出一个简单的状态机,A->B->C->A->...
状态C应该是由状态B转换而来,若是在记录信息中发现是通过A转换而来的,那说明状态A的设计出现了差错,问题定位的范围从一整个系统缩小到了一个状态。
明确的职责划分
状态机当中的各个状态,应该对应所要做的一件件事。
你应该不止一次听说过单一职责原则,我们也应该让每一个状态尽可能只完成一件事情,而不要让一个状态变得过分复杂。
明确了每个状态所要负责完成的事情,如果你是一个leader,接下来就可以给你的手下分配状态了,每个人只需要完成自己负责的状态。
这样明确的指责划分,有助于系统的联调。
我们在上面已经给出了具体例子,根据设计,状态C不应该由A转换而来,若确实发生了这样的转换,我们可以快速找到这个状态的负责人,询问他这么做的意图是什么,是考虑不周全,还是图方便,亦或者是什么别的原因。
同时,状态的具体细节由每个负责人把控,只要在不发生错误的状态转换,状态内部即便玩成花了,在整体上还是保持统一的视图,只不过受苦的还是这个状态目前的负责人或未来的负责人。
但只要状态的划分能满足单一职责原则,想必即便是由于负责人的水平所导致的问题,也是比较容易优化的,因为问题范围已经缩小到了单个状态,状态转换不出错,就不会影响到系统整体功能的正确性。
更丰富的视角
我们在前面已经讨论过了,Everything is a State Macine
在程序设计的过程中,若是遇上了一些困难,导致思路阻塞,不妨考虑换一种视角,采用状态机的方式来进行思考。
以算法题为例,删除带头节点的链表L的一个节点P,我们会考虑被删除节点的前一个节点Q的连接关系的改变,就这个节点Q而言,它的状态发生了转换,Q->next = P->next;
而对于节点P而言,它的状态也发生了转换,delete P;
对于这个链表L而言,它的状态也发生了变化,L->size = L->size - 1;
我们通过思考了三个状态转换,得到了一个算法的核心逻辑。
请注意,我们将状态进行了明确的职责划分,一个状态负责Q,一个状态负责P,一个状态负责L。
每个状态只负责极其有限的工作,这样对思考逻辑非常有帮助,事情越少越容易想清楚。
当然这道题属于是极其简单的水平,从中能获取到的感悟并不多。
也许你可以考虑试试稍微复杂一些的动态规划问题,动态规划解题的关键往往是状态转移方程,这个方程就是在描述状态是如何构建的,很贴合状态转移的定义,例如dp[i][j] = dp[i][j-1] + dp[i-1][j],意在说明状态(i,j)由状态(i,j-1)和状态(i-1,j)共同构建转移而来。
并不是说动态规划的问题可以完全依靠状态机来解决,而是在动态规划问题的解决办法里,经常性的出现状态机的背影,某些时候从状态机入手,会为你带来一些思路,或者有助于你理解题解给出的状态转移方程。
再考虑一个例子,编译器设计当中的前端,再具体一些,词法分析/语法分析。
以C++的if语句来分析,当我们读取到if这个关键字后,下一个状态应该是一个左括号(,如果状态转换到了一个变量名上,就代表发生了一个语法错误,它看起来像是这样:if flag,正确的应该是这样:if (flag)。
研究一下编译原理会让你受益匪浅,看看状态机在编译器设计当中的应用,加深对状态机的理解。
状态机的设计与实现
在初步感受了状态机后,我们进一步了解了状态机的带来的好处,此时我们有足够的理由和动力来使用状态机设计程序了。
我认为,状态机是一种思考方式,它的实现并不唯一,主要取决于对状态机本身的理解。
这也是为什么可以在各种地方看到各式各样的状态机实现,比如有电路设计里面的三段式状态机,也有设计模式提到的状态模式,对吧。
所以本节的目的之一是看看状态机具体有哪些实现方法的,再就是抛砖引玉,从实际案例当中领悟实现状态机的要领,以后你就可以根据具体需求,选择合适的实现方法。
三段式状态机
Verilog是一种数字电路的描述语言,我们会以Verilog来描述三段式状态机的电路结构,所以此处是介绍一种用数字电路来实现状态机的办法。
顾名思义,三段式状态机就是把实现分成三部分来考虑,事实上也确实有两段式/一段式,但是三段式胜在逻辑更加清晰,更加易读。
在一堆软件内容中插入对硬件的描述,看起来是有一些突兀,不过这应该更能突出,状态机本质是一种思想,用来指导系统设计,也更能突出状态机的强大,上到软件,下到硬件,都是可行的。
我们考虑一个简单的状态机:A->B->C->A->B->C->...
verilogmodule FSM( input clk, input reset, output res ); parameter A = 2'b00; parameter B = 2'b01; parameter C = 2'b10; reg [1:0] state; reg [1:0] next_state; always @ (posedge clk or posedge reset) begin if (reset) state <= A; else state <= next_state; end always @ (*) begin case (state) A: next_state = B; B: next_state = C; C: next_state = A; default: next_state = A; endcase end assign res = (state == C); endmodule
我们来看看状态转移是如何实现的:state <= next_state;
将next_state连接到state,在时钟上升沿到来时,就会发生实际的“赋值”,也就是转换到下一个状态。
再来看看状态转移的条件是如何表达的:
verilogcase (state) A: next_state = B; B: next_state = C; C: next_state = A; default: next_state = A; endcase
通过使用一个case结构,来表达所有可能的状态以及状态转移条件。
至此,一个数字电路版的状态机就实现完成了,描述状态机的关键就是状态和状态转移条件,而这两点都已经呈现出来了。
没有想象中那么复杂困难,相反是简洁明了的,即便对verilog的语法细节不了解,也能大概看出点东西来。
责任链模式
我们将视角转回软件方面,从设计模式入手。
首先要介绍的一种设计模式是责任链模式,我个人认为这是一种非常直观且简单的状态机实现。
责任链模式的核心思想是将请求的处理职责分散到多个对象中,每个对象只处理自己职责范围内的请求。
如果一个对象无法处理请求,它会将请求传递给链中的下一个对象,直到请求被处理或链的末端。
简单的实现
cpp/*
* C++ Design Patterns: Chain of Responsibility
* Author: Jakub Vojvoda [github.com/JakubVojvoda]
* 2016
*
* Source code is licensed under MIT License
* (for more details see LICENSE)
*
*/
#include <iostream>
/*
* Handler
* defines an interface for handling requests and
* optionally implements the successor link
*/
class Handler
{
public:
virtual ~Handler() {}
virtual void setHandler( Handler *s )
{
successor = s;
}
virtual void handleRequest()
{
if (successor != 0)
{
successor->handleRequest();
}
}
// ...
private:
Handler *successor;
};
/*
* Concrete Handlers
* handle requests they are responsible for
*/
class ConcreteHandler1 : public Handler
{
public:
~ConcreteHandler1() {}
bool canHandle()
{
// ...
return false;
}
virtual void handleRequest()
{
if ( canHandle() )
{
std::cout << "Handled by Concrete Handler 1" << std::endl;
}
else
{
std::cout << "Cannot be handled by Handler 1" << std::endl;
Handler::handleRequest();
}
// ...
}
// ...
};
class ConcreteHandler2 : public Handler
{
public:
~ConcreteHandler2() {}
bool canHandle()
{
// ...
return true;
}
virtual void handleRequest()
{
if ( canHandle() )
{
std::cout << "Handled by Handler 2" << std::endl;
}
else
{
std::cout << "Cannot be handled by Handler 2" << std::endl;
Handler::handleRequest();
}
// ...
}
// ...
};
int main()
{
ConcreteHandler1 handler1;
ConcreteHandler2 handler2;
handler1.setHandler( &handler2 );
handler1.handleRequest();
return 0;
}
以上责任链模式的实现来自于开源项目:4.3k star (2025.1.18)
https://github.com/JakubVojvoda/design-patterns-cpp.git
在《Design Patterns in Modern C++20》这本书当中对于责任链模式的实现,也提到了一种更简单的方式,就是采用一个数组/链表/哈希表之类的存储容器,将所有的责任函数放在一块,然后遍历即可。
代码已经可以很好的展现责任链模式所想要表达的东西了,就是一件事情接着一件事情做。
从状态机的角度来理解,那就是一个状态转换到下一个状态,所以一整个责任链就是状态机中所有状态的容器。
但是你可能有一个疑惑,难道没有转移条件吗?
那我们会说,设置下一个责任就是在表达状态转移条件:handler1.setHandler( &handler2 );
根据某些条件是否满足,来选择下一个要执行的责任函数,就是在表达状态转移。
还没尽兴?看看Linux
我们会更好奇,责任链模式的一些实际的业务场景。
这里我提供一个稍微复杂一些的案例,Linux内核的网络子系统。
既然谈到内核,必然是需要展现内核源码的,但是我们的重点并不是研究内核的实现,所以不会过多讲解其中的细节,对这方面感兴趣的可以从其他资料中自行研究,同时我们会把控程度,展现我们关心的状态机主题。
网络子系统最关心的内容之一就是网络数据包的处理,我们也打算介绍这一过程。
众所周知,计算机网络被分成了很多层次,每一层都有各自关注的重点。
当收到一个数据包后,会从最底层开始,一层层往上传,数据包会在每一层得到一部分的处理。
而发出一个数据包,是从最上层往下层传,这是一个相对的过程。
即便是分了层,但在每一层当中,还是存在大量的协议。
所以一个必然需要考虑的问题就是,数据包在经过本层的协议处理之后,应该如何抵达下一层的协议?
注意,是由网络协议自身决定接下来应该去往哪个协议的,所以这里更应该关注的点是,数据包具体是如何传给另一个协议进行后续处理的,来看看Linux内核的实现。
这里的参考材料是《深入Linux内核架构》。
我们只考虑数据包从网络层到传输层的传递,这样会更简单一些。
这一流程当中关注的重点是数据包的路由处理,如下图所示。
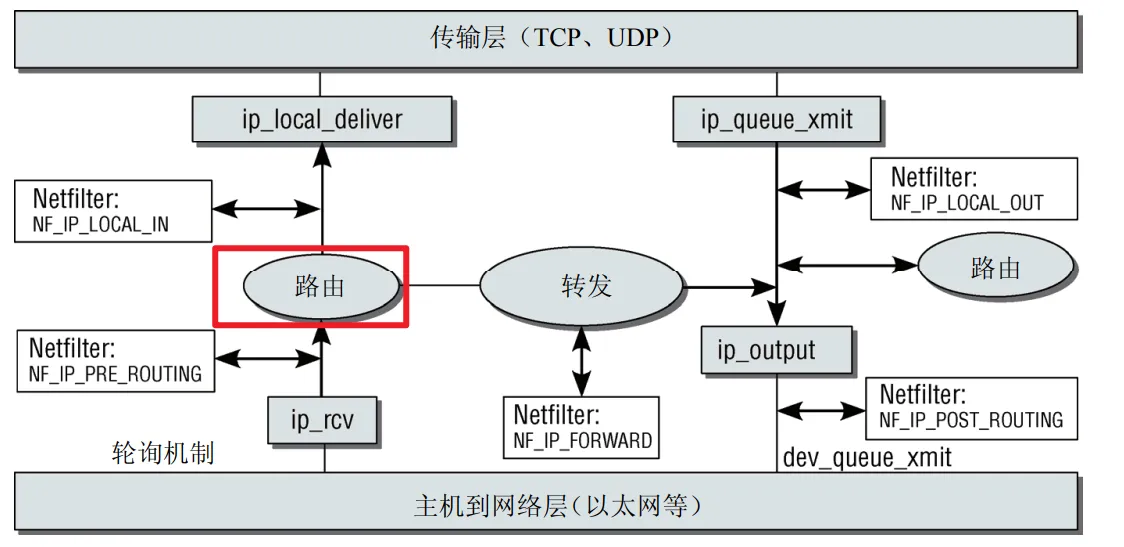
内核当中的ip_route_input函数是选择路由的起始点,路由选择的结果是,选择一个函数,进行进一步的数据包处理。
路由结果和数据包是相关联的,每个数据包都会有一个路由结果,内核中代表数据包的结构是sk_buff,它其中的dst成员指向一个代表路由结果的dest_entry结构的实例,而该实例的内容是在路由查找期间填充的。
cpp// include/net/dst.h
struct dst_entry
{
struct net_device *dev;
int (*input)(struct sk_buff*);
int (*output)(struct sk_buff*);
struct neighbour *neighbour;
};
函数指针input和output分别用于处理进入和外出的数据包,根据数据包的类型,会对input和output指定不同的函数:
-
对需要交付到本地的分组,input设置为ip_local_deliver函数,而output设置为ip_rt_bug函数
-
对于需要转发的分组,input设置为ip_forward函数,而output设置为ip_output函数
到这其实就够了,这其实就是一种责任链模式的实现,上面提到的input和output函数指针就是所指向的下一个职责函数,根据数据包的不同,这个两个函数指针会指向不同的职责函数,这也是状态转换的体现。
状态模式
责任链模式算是一个开胃小菜,在设计模式当中,是有一个非常正统的对状态机的实现的,那就是状态模式。
在《Design Patterns in Modern C++20》当中,提到了一种简单的实现,事实上这种实现我们也已经在verilog那感受过了;同理,在C++当中,会使用switch-case语句来实现。
但是在之前我们也提到过,状态机是可以作为一个观察者,来记录所有状态转换的过程的,最典型的用处是辅助debug。
当然,我们可以实现一个更通用的状态机模型,适用更广泛场景的同时,也展现我们状态记录的过程。
cpp#include <map>
#include <mutex>
#include <queue>
#include <format>
#include <string>
#include <chrono>
#include <vector>
#include <thread>
#include <memory>
#include <sstream>
#include <iostream>
#include <functional>
#include <condition_variable>
struct State;
struct StateMachine;
struct State {
std::string_view name {};
State() = default;
State(std::string_view n) : name{ n } {}
virtual ~State() = default;
virtual std::string_view switcher(std::shared_ptr<StateMachine>) {
return "";
}
};
struct StateMachine : public std::enable_shared_from_this<StateMachine> {
std::map<std::string_view, std::shared_ptr<State>> states {};
std::string_view cur;
std::string_view exit;
StateMachine() = default;
virtual ~StateMachine() = default;
template<typename T>
StateMachine& addState(std::string_view name) {
if (!states.contains(name)) {
states.insert({
name,
std::make_shared<T>(name)
});
}
return *this;
}
StateMachine& setStartState(std::string_view name) {
if (states.contains(name)) {
cur = name;
}
return *this;
}
StateMachine& setExitState(std::string_view name) {
if (states.contains(name)) {
exit = name;
}
return *this;
}
void run() {
while (cur != "" && cur != exit) {
auto state = states[cur];
if (auto rt = state->switcher(shared_from_this()); rt != "") {
cur = rt;
}
}
if (cur != "" && cur == exit) {
states[cur]->switcher(shared_from_this());
}
}
};
我们定义了两个接口,一个是状态机,还有一个是状态,在状态机中通过状态的名字来管理状态。
通过继承State并完成对虚函数Switch的重写,来定义自身状态的具体逻辑,同时给出应当转移的下一个状态(通过返回下一个状态的名字)。
对于状态机来说,它只需要考虑如何转移状态(将Switch函数的返回值赋给当前状态cur),并在合适的时候停下来即可(抵达终态时),这就是while循环当中所表达的。
因此,在每次循环的末尾,状态机都有机会执行状态的记录,如果有需要的话,你可以进行你感兴趣的改造。
来看看具体是如何创建状态和状态机,并构建它们之间的联系的。
cppint main() {
std::jthread t1([]() {
transactionStateMachine->
addState<StateA>("A").
setStartState("A").
addState<StateB>("B").
addState<StateC>("C").
addState<StateD>("D").
addState<StateE>("E").
addState<StateQ>("Q").
setExitState("Q").
run();
});
std::jthread t2([]() {
logStateMachine->
addState<StateJ>("J").
setStartState("J").
addState<StateK>("K").
setExitState("K").
addState<StateH>("H").
run();
});
return 0;
}
注意,我创建了两个线程,每个线程跑一个状态机,这也符合我们的理论,一个状态机专注一件事会更好。
但是,多线程之间少不了交互,我们如何完成多线程之间的交互呢?
在《C++并发编程实战 第二版》一书当中,给出了一个使用状态机来完成多线程程序设计的实例,在这个实例当中是通过消息队列来进行多线程之间的交互的。
而我在此处也打算根据我自己的理解,来复刻这一实现,但是会简化一些,突出状态机的主题,又不失体现状态机在复杂系统设计当中的好处,多线程就是一种典型的复杂系统。
不过,即便你不需要多线程,上面给出的模型也是适用的,这是一个通用设计,并不局限于某个具体系统。
你可以在这里查看完整的代码实现,该系统的业务需求是实现ATM存钱取钱,并记录所有的操作。
看看两个关键的状态J和E,这两个状态展现了多线程之间通过消息队列进行交互的细节。
cppstruct StateJ : public State {
using State::State;
virtual std::string_view switcher(std::shared_ptr<StateMachine> _sm) {
auto&& sm = logStateMachine;
std::shared_ptr<Command> cmd = nullptr;
{
std::unique_lock lock(sm->mtx);
sm->cond.wait(lock, [&]() {
return !(sm->q.empty());
});
cmd = sm->q.front();
sm->q.pop();
}
if (cmd != nullptr) {
sm->cmd = cmd;
if (cmd->type() == 0)
return "K";
else if (cmd->type() == 1)
return "H";
}
return "";
}
};
struct StateE : public State {
using State::State;
virtual std::string_view switcher(std::shared_ptr<StateMachine> sm) {
auto& data = transactionStateMachine->data;
if (data.opcode == 1) {
data.money += data.cnt;
println("Save money: {}, current money: {}", data.cnt, data.money);
logStateMachine->sendWriteLogCommand(std::vformat(
"Save: {}",
std::make_format_args(data.cnt)
));
}
else if (data.opcode == 2) {
if (data.cnt <= data.money) {
data.money -= data.cnt;
println("Take money: {}, current money: {}", data.cnt, data.money);
logStateMachine->sendWriteLogCommand(std::vformat(
"Take: {}",
std::make_format_args(data.cnt)
));
}
else {
println("Not enough money: {}", data.money);
}
}
else {
println("Invalid opcode: {}", data.opcode);
}
return "C";
}
};
在状态E中,每当执行存钱或取钱的操作,都会向logStateMachine通过sendWriteLogCommand函数发送一个写入日志的命令消息;而在状态J中,通过sm->cond.wait在等待着各种命令消息的到来,然后从消息队列中取出处理。
编译和运行结果如下所示,还是比较容易理解的。
shell% g++ state_machine_test.cpp -std=c++23 -o state_machine_test
% ./state_machine_test
Input your id:
test666
Input your password:
1638
Login success
[0]Quit [1]Save [2]Take [3]Show
Choose operate:
1
Input money:
234
Save money: 234, current money: 334
[0]Quit [1]Save [2]Take [3]Show
Choose operate:
2
Input money:
500
Not enough money: 334
[0]Quit [1]Save [2]Take [3]Show
Choose operate:
2
Input money:
100
Take money: 100, current money: 234
[0]Quit [1]Save [2]Take [3]Show
Choose operate:
2
Input money:
40
Take money: 40, current money: 194
[0]Quit [1]Save [2]Take [3]Show
Choose operate:
1
Input money:
24
Save money: 24, current money: 218
[0]Quit [1]Save [2]Take [3]Show
Choose operate:
3
Current money: 218
[0]Quit [1]Save [2]Take [3]Show
Choose operate:
0
Quit Transaction...
Print Log:
[Level 0] [2025-01-19 17:03:06] Save: 234
[Level 0] [2025-01-19 17:03:15] Take: 100
[Level 0] [2025-01-19 17:03:19] Take: 40
[Level 0] [2025-01-19 17:03:26] Save: 24
无处不在的状态机
最后,我们再展现两个状态机应用的实例,你应该早就接触过了,但可能还没意识到。
进程在干嘛
进程本身也是具有状态的,用来表明当前进程在干什么事,典型的比如,执行阻塞的IO操作后,进程会被挂起等待,进入阻塞态。
在参与操作系统理论课程的学习后,应该能画出大致的状态转换图,如下所示(网上搜的,不影响理解)。
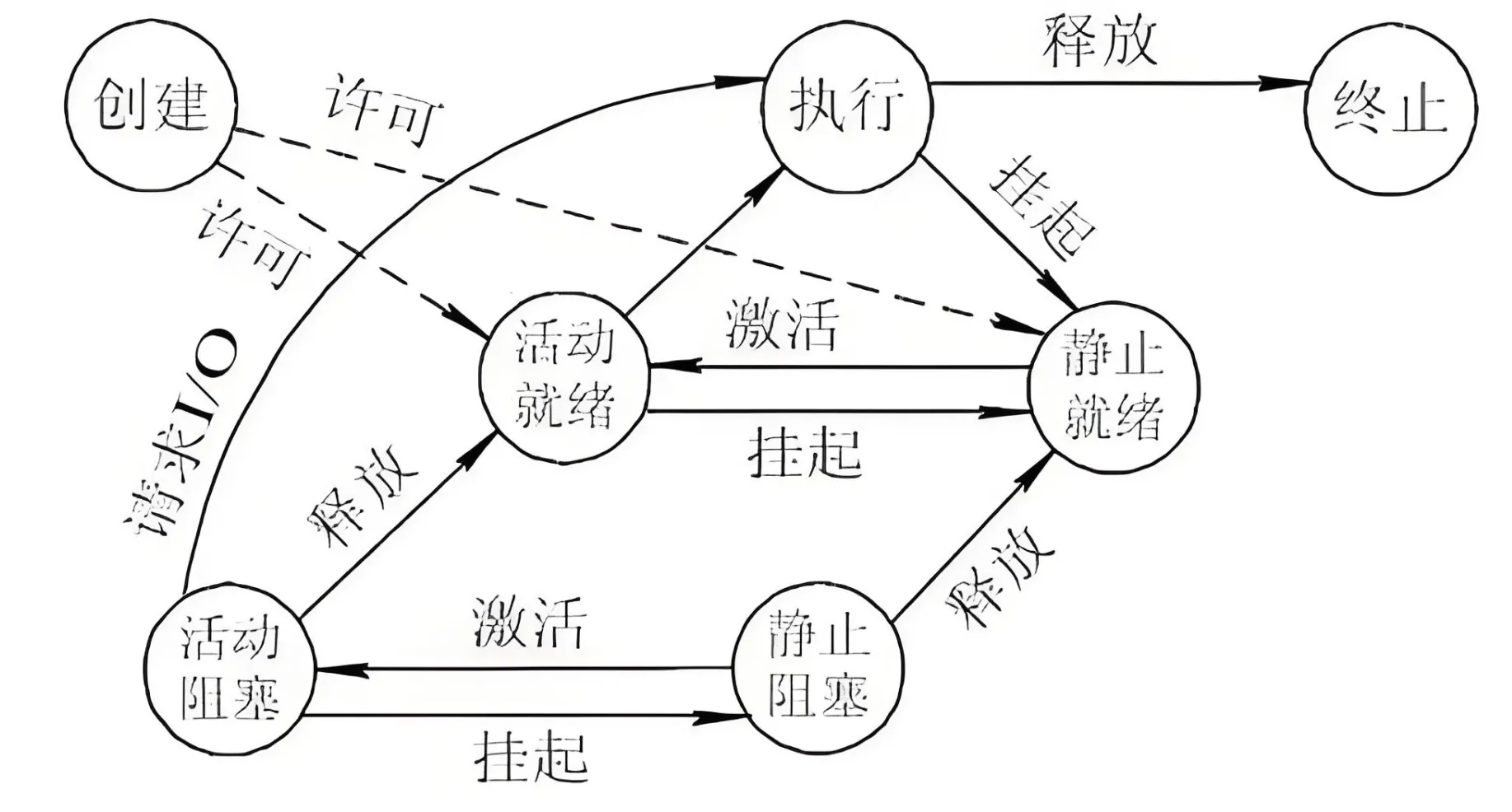
这是状态机理论对操作系统设计指导的一方面,状态机其实早就融入到各个细分领域当中了。
耳熟能详的TCP
TCP当中存在多个可能的状态,为了实现起来更加清晰,大家也是为其画出了状态转移图,如下所示,该图来自于《TCP IP详解卷1》:
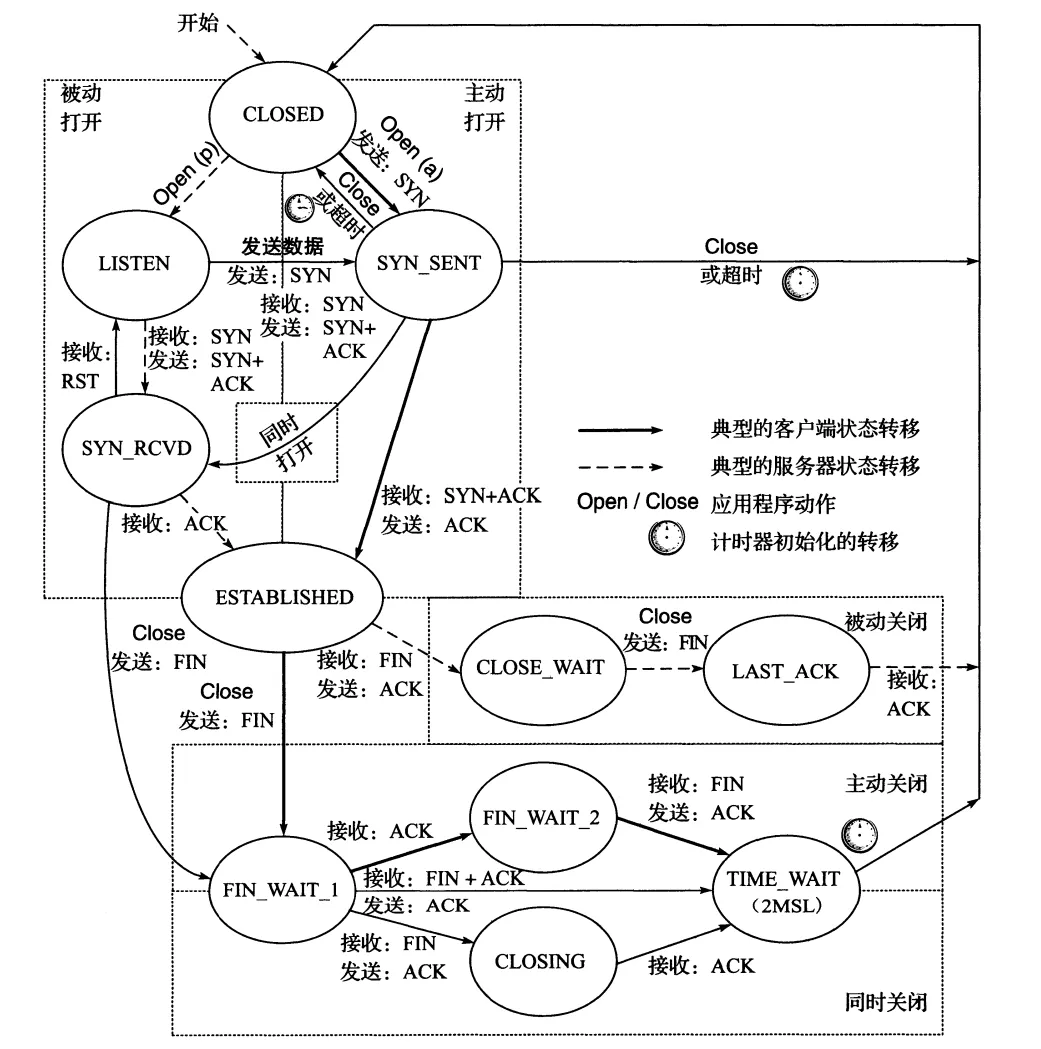
状态机被引入进了复杂网络协议的实现当中,我认为这是很有说服力的,这也能反映出状态机在梳理逻辑方面的优势。
最后的思考
状态机是一种思考方式,用于拆解复杂系统,有助于我们理解一个复杂的系统,或是在设计时,将各个功能模块划分的更加独立,各司其职,分工明确。
本文作者:Test
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!